Factors for a successful organization-wide shared information service
Abstract:
The need for a high quality information delivery service is critical in real-time applications supporting safety and cost optimization, such as air traffic management.
How can a large, complex organization deliver a shared information service to satisfy its core operations and analytic use cases, particularly when it already has a legacy of IT systems and a service that must operate without downtime during the period of transition?
This paper summarizes the experiences of 25 organizations as they struggle with the physical realities of information management and the cultural challenges of becoming a data-driven organization with a shared information service at its heart.
It characterizes the factors that contributed to the success or failure of their shared information service. It considers how the projects were structured and led, the way information is governed, the standards used in the service and the way the organization was prepared for the transition as well as the technologies employed.
I. Introduction
Over the last three to four years, the term “big data” has become recognized as a key challenge within both commercial and public sector organizations. Big data is a misleading term because many of these organizations had already been processing large volumes of data in their operational and data warehouse systems and as a result had considerable skills in managing their data.
However, big data does not just refer to volume of data. It also encompasses a high variety of data sources and consumers along with the need to support a range of velocities for both data capture and responses, stretching from hard real-time to batch.
It is when the variety and the velocity of data are added to the large volume that the problem is characterized as big data. New approaches are needed to process this data since a big data solution must be able to blend all types of structured and unstructured data whilst also supporting both operational and analytical (batch, historical) workloads.
Despite claims of various technology advocates, there is no single technology that can support this range of requirements. In addition, even within a single organization, there are many views of what concepts and data values mean due to the different perspectives that each part of an organization works with.
So any shared information service must design the solution holistically, taking the organizational dynamics as much into account as the technology.
II. Background of the Study
Over the last 3 years, I have had the privilege of working with a wide variety of different organizations on their information strategy, architecture and governance.
This paper distills the observations I have made whilst working with 25 of these organizations who were embarking on the development and operation of an enterprise-wide shared information service.
The organizations come from the banking, insurance, industrial, telecommunication, distribution and public sectors. Each of them is complex with multiple independent operating units (or silos) that need to share information. The majority of these organizations are dispersed across multiple countries that each has their own regulations and data sovereignty laws.
Although the organizations are from different industries (affecting the subject areas of the data they focus on and the regulations they must support) there is surprising commonality in the problems they are trying to address and the approaches they use. Most of them need their shared information service to cover core operational data such as people, organizations, business transactions, reference data and data from external organizations. They have deep skills in managing traditional structured data, but want to extend their capabilities to extract value from log files, documents, emails, audio recordings and video [1].
Many of these organizations wish to become data-driven and use analytics to support their business operations and decision-making [2].
- They want their employees to be self-sufficient in data. This means they can locate and use the information they need either for routine operations, ad hoc decision making or during an unexpected incident.
- They want their operational processes to work with authoritative data. This is data that contains the official, best available values that the organization has.
- They want their data management processes to be as timely and cost-effective as possible.
- They want to comply with necessary regulations and also deliver their brand value and ethics through their use of data.
- Finally, they want to continuously improve their operation through the analysis of data generated by their operational processes (digital exhaust) and through the use of analytical decision models in their automated processes.
These are all ambitious goals and the resulting projects are often multi-year. The study supporting this paper comes from my observations of the project dynamics and approaches these organizations take at key stages of their journey that is rolling out their shared information service.
At the time of writing this paper, two of the 25 projects have failed and been stopped. The rest are still on going and their statuses range from highly successful to struggling.
The reasons for this are complex, but there are similar factors that I see in the organizations that are successful. By contrast, the organizations that are unsuccessful typically have neglected to implement a key initiative or design principle that the successful organizations have put in place, rather than making mistakes or making poor technology choices.
III. Observations
The observations from the study cover the technology, architecture, standards and organizational aspects of the shared information service.
A. Use of technology
Organizations that put all of their faith in a single technology to deliver all of the use cases for a shared information service typically hit problems in performance, cost or capability. For example:
- Big data is typically associated with specific technologies such as Apache Hadoop. However, experience has taught many organizations that although Apache Hadoop can deliver a cost effective batch-oriented approach to managing data at scale, it is not on its own sufficient to deliver advanced information services to an organization that needs data to drive its business.
- Technology for supporting a service-oriented architecture (SOA) such as messaging, connectors, adapters, enterprise service bus and service directory are insufficient to support a shared information service. SOA technology focuses on defining the format and structure of services. This is necessary, but a shared information service must also focus on managing the data values that pass through the service interface [3].
- Data integration technology provides the capability to copy and synchronize data between different systems. Data virtualization technology can blend data from different systems on demand, without taking a copy. Each approach has their uses, depending on how rapidly the values are changing, how consistent the data sources are, how often the data is queried and how much transformation is needed to deliver appropriate data to the destination.
This establishes our first principle for a shared information service. A successful shared information service must blend SOA technology with information management technology such as data integration and data virtualization technology, master data management, reference data management, caching and information governance technology [4].
Using multiple technologies adds complexity to the shared information service. Often its end-to-end operation goes beyond the knowledge and understanding of a single person. A team of people with different specialisms is needed to integrate the technology together so that the resulting service operates consistently and collectively meets its service level agreements (SLAs).
Our second principle states that designing a multi-technology service requires a pattern-based design process. The design patterns offer a common language to discuss design options that are independent of the technology and create a clear definition of the intended function [5].
This technological complexity can not be exposed to the users of the shared information service. They need simple, consistent interfaces to locate and extract data. However, the consumers of data from the service need transparency on where data came from and the transformations that were made to it by the information service in order to determine that the data they are using is fit for purpose. Similarly, information owners need to understand how their data will be used before they are willing to connect their systems to it.
Our third principle for a successful shared information service states that it must deliver three types of data:
- The organization’s data used for its operations and analytics.
- Metadata that describes where this data comes from, where it flows to and how it is being managed, transformed and processed inside the shared information service.
- Technical blueprints and operational logs that enable the technical team to understand how the shared information service is constructed and how it is operating. Without this, it quickly becomes impossible to evolve the service over time.
B. Anatomy of a shared information service
The metadata, technical blueprints and operational logs collectively explain how the different parts of the shared information service are delivered. Organizations working on the shared information service focus these definitions on how systems connect to the shared information service and exchange data; how data flows through the information service; the lifecycles of the data and the processes using the data; and the special management necessary for different types of data.
1) Services and endpoints
The fourth design principle of the shared information service is that it offers well-defined interfaces to access and update the shared information. The more successful organizations include in this definition:
- The structure of interface in terms of the operations that can be called and the parameters passed.
- Descriptive information (metadata) about the data passed in the parameters covering the meaning of the data elements, the valid values and the profile of these values.
- Description of the context information from the caller that must accompany each request. This context information typically includes authentication tokens along with identifiers and type information for the process that is using the service. It may also include location or other information about the caller. The context information is used to drive governance functions in the underlying service.
- Description of the expected interaction patterns of use of related operations offered by the service.
Systems connecting to the shared information service often are using different data identifiers and structures and will need to map between their data representations and those of the shared information service. So published best practices for implementing these “adapters” can speed up the adoption of the shared information service.
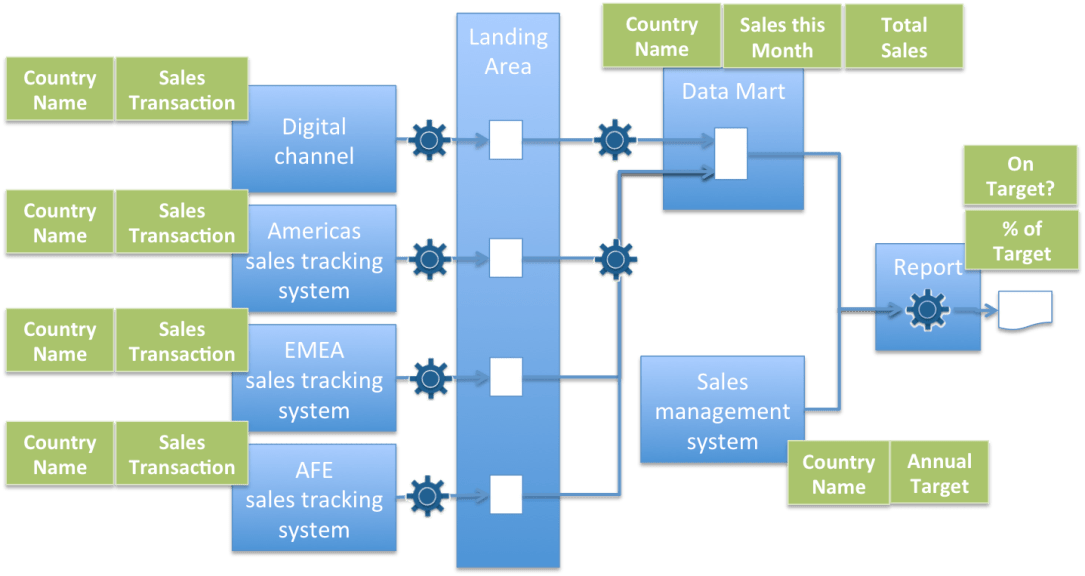
2) Information supply chains
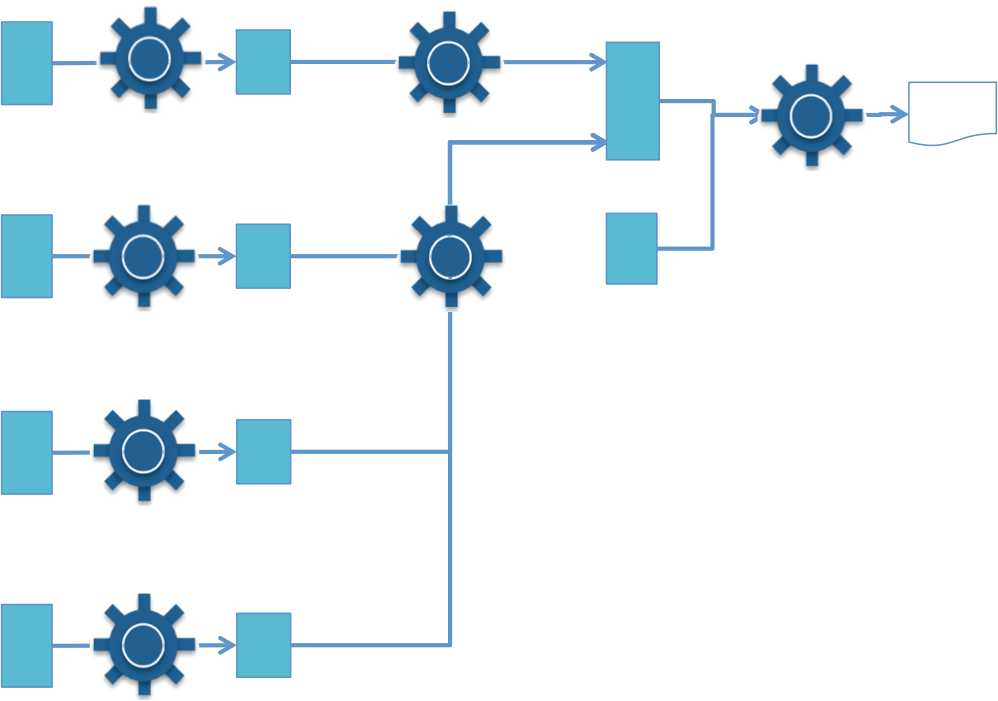
The flow of a particular type of information between systems is called its information supply chain [5]. Along the information supply chain, different processes transform, filter, combine and deliver data. Where a shared information service is in operation, the information supply chains pass from systems pushing new data values into the shared information service, through the stores and processes within the shared information service and to the systems consuming the data. The information supply chain will follow a different path for different types of data.
The design of an information supply chain is captured in metadata and is used to:
- Understand the impact of change to the shared information services.
- Understand the impact of an outage within the shared information service.
- Demonstrate the integrity of data provided through the shared information service.
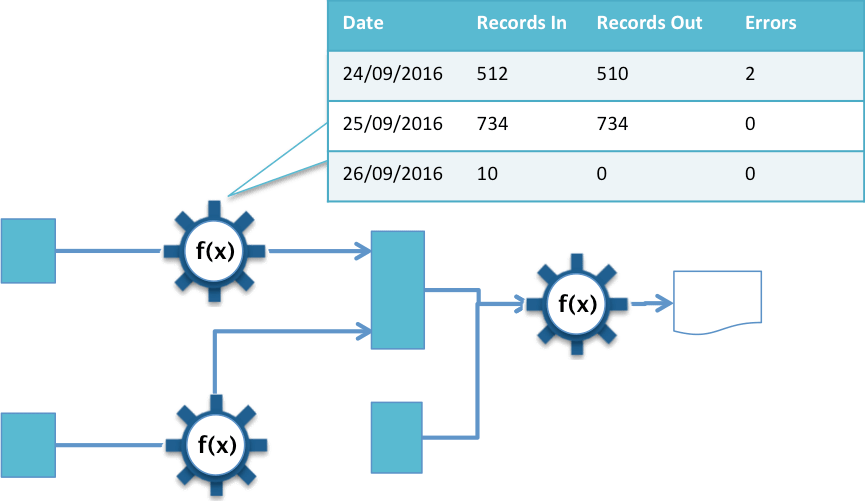
- Track the correct operation of the shared information service by comparing the operational logs against the information supply chain design.
The information supply chains provide the core definition of the behavior of the shared information service. Thus designing with information supply chains is the fifth design principle of a successful shared information service.
3) Key lifecycles
The data and processes supported by the shared information service are operating a number of different lifecycles. These lifecycles determine how the data changes over time.
- Software development lifecycle – this lifecycle controls code changes to the shared information service. New data types, interfaces and internal capability are introduced through the software development lifecycle.
- Analytics development lifecycle – this lifecycle controls how analytics are developed and deployed using the data from the shared information service. Analytics enables an organization to continuously improve its operation, innovate and understand risks. The shared information service needs to include the ability to retain historical values for the data flowing through it, and its operational logs so that comparisons can be made over time [6].
- Policy lifecycle – this lifecycle evolves the governance policies and related definitions for the shared information service.
- Information lifecycles – not all data is the same. Some data is long lived and used in many systems. Other data is maintained within a small number of systems and then distributed through the shared information service. Other information never changes because it represents an event that occurred. Each type of data has a natural lifecycle that determines how it is typically created, maintained and deleted. The services of the shared information service need to support these lifecycles in the interfaces and internal processes.
These lifecycles define many of the interaction patterns with the shared information service. Design principle six recognizes that the more successful organization design these lifecycles into the shared information service early in its lifetime so that the appropriate organizational adjustments can be made to support any new roles they create.
4) Reference data
Every shared information service needs reference data to define the valid values for particular types of data. This reference data may reside outside of the shared information service but it is more coherent if the shared information service team is responsible for managing this reference data, and also provides mapping services for connected systems to maintain the mappings between the values they use internally and the values used in the shared information service.
Design principle seven states that a shared information service should maintain its own reference data and provide mapping services to allow a connected system to maintain relationships between their entity identities, code table values and other reference data values and those used by the shared information service. The benefit of this is:
- It is cost-effective since this mapping service only has to be implemented once – rather than in each connected system.
- It speeds up the development for the adapter for a system that is to be connected to the shared information service.
- It provides a useful debugging and analysis resource for end-to-end diagnosis and optimization.
C. Common information model(s)
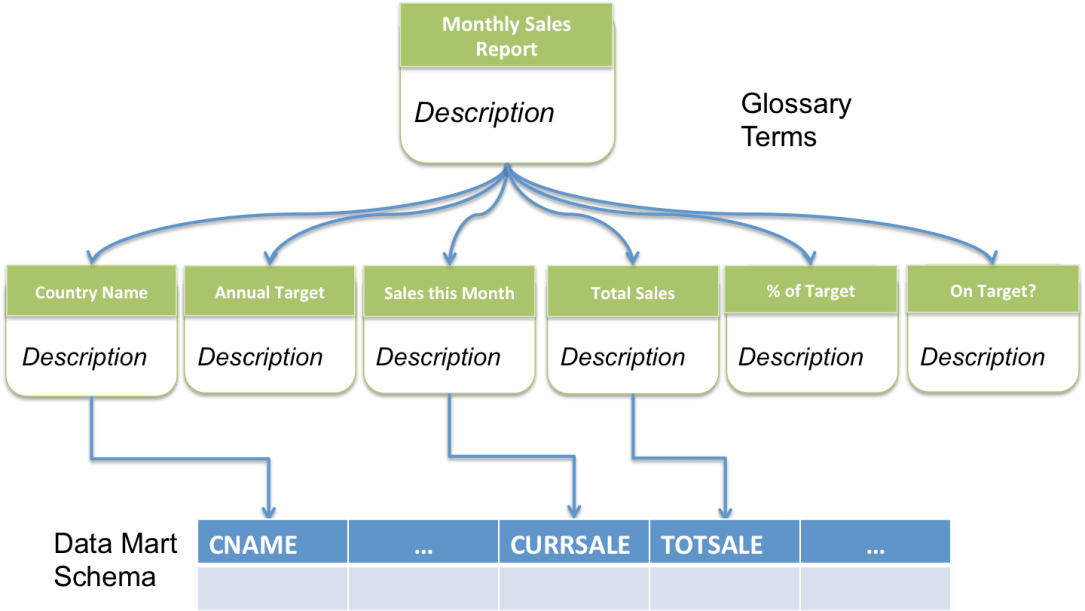
Design principle eight states that the shared information service should offer a harmonized definition of the information it shares. This definition is known as a common information model [7]. The common information model is misnamed because it is actually a collection of models offering difference views or perspectives of the data. These models are linked together through metadata to show how the corresponding perspectives related to one another. The common information model for a shared service should include:
- A glossary of terms describing each of the data attributes and related concepts in prose. This glossary is used by everyone involved in the project to understand the meaning of data supported by the shared information service.
- Subject areas and spine objects that group the glossary terms into topics and flattened business objects. This structuring is useful when assigning data subject matter experts and owners to the shared information service’s data landscape and as a starting point for data modelling.
- Logical data element models detailing different levels of detail about a particular entity. Data element models are used as definitions for the parameters on the service interfaces. Typically there would be a data element model for each significant entity that describes the structure for identifying the entity, another for a summary of its principle attributes and then additional definitions coving increasing levels of detail.
- Logical data models for any data stores maintained by the shared information service.
- Physical models of service interfaces and data stores maintained by the shared information service.
D. Metadata management
The term metadata has been mentioned a number of times already. It describes the types of data supported by the shared information service, the valid values of this data, where it comes from (lineage), how it is structured by the different interfaces and stores and the processes that shape it.
Support for metadata as a first class capability of a shared information service is our next design principle (number nine). The focus it creates ensures a clean and clear definition of the data types and services. It also improves the usability of the shared information service.
1) Metadata catalogs
An organization-wide shared information service typically supports a wide range of services. The metadata of the shared information service can provide a data-centric catalog to the interfaces that helps to guide people to the appropriate service for their need. For example, they may be interested in understanding the refueling facilities at an airport. The metadata catalog would offer a search facility that would use the links from the glossary terms to the parameters on the service interfaces to locate
2) Metadata use and operation
Inside the shared information service, the metadata is driving the behavior of the internal processes and the access interfaces. For example, it may be used to control how data is routed, who has access to it and how long it is retained.
Many organizations implementing a shared information service quickly recognize the value of a comprehensive metadata capability. However, some make the mistake of underestimating the effort to maintain the metadata. Since technology from multiple vendors is likely to employed in the shared information service, it is important that metadata management is open and automated within that technology and related tools. Otherwise the shared information service project team must plan for the effort taken to maintain and manage this metadata [8].
E. Business-led governance
Since data drives an organization, it makes sense that the business is leading the governance program that controls it. To make this actionable, the shared information service needs governance functions that are driven by metadata and reference data settings that appropriate business leaders control through well-defined processes. This is design principle ten.
1) The role of classification
Classification of the different types of data is enabled in the metadata capability. Classification allows the appropriate business owner for a subject area to identify where data that requires special care is located. This includes different levels of confidentiality, retention requirements, confidence and integrity in the data supplied through the service. Linked to the different levels of classification are the rules that must automatically execute within the shared information service whenever data with that classification is encountered [9].
2) Owners, custodians and consumers
A key role of information governance is to assign roles and responsibilities to people and systems plus monitor and measure compliance. The metadata capability in the shared information service should manage the allocation of people to those roles that relate to data management and use and provide the processes they will use to perform these roles.
3) Self-service
Self-service describes a set of services for people to locate and extract sets of data values from the shared information service. These extracted values can be used for ad hoc analysis/investigation, analytics development and test data generation.
F. Iterative development
Given the size of an organization-wide information service, it needs to be delivered as a series of iterations – typically every three months or so. Some organizations iterate faster than that, but discover that the connected systems find it hard to keep up with a faster schedule. The pace of delivery needs to match the ability of the consuming systems to accommodate each iteration.
Due to the shared nature of the service, new developments need to be made openly with plenty of opportunity for review and feedback. The more advanced organizations have three staggered parallel tracks operating.
- Data definition track – the most advanced track creates the common definitions for data passing through the shared information service.
- Architecture track – the architecture track designs the technical implementation of new capability within the shared information service. They use the definitions from the data definition track in the design of the interfaces and stores within the shared information service.
- Delivery track – This team drives the rollout of the shared information service and assists the teams connecting their systems to the shared information service.
The advanced work of the data definition and architecture tracks reduces the rework needed in the delivery track as it has clarity on the data and interfaces it is delivering. Using staggered parallel tracks for data definition, architecture and delivery is design principle eleven.
G. Leadership and management
Many organizations are hierarchical in nature. Data flows laterally between an organization’s internals silos in a shared information service and there must be consistency in the way information is maintained and used within each silo.
The result of an organization-wide shared information service is typically deeply disruptive to any organization, particularly those that have been highly decentralized and/or focused on functional, hierarchical command and control. This is because the way resources are organized and allocated changes, resulting in an equivalent change in the positions of authority and influence. This change can create huge resistance and inertia in the organization as people fear for their positions and future.
As such, the shared information services that had clear, visible support from the top of the organization met least resistance. This leadership included participation in studies and decisions about the service, communications to all employees, investment and recognition to initiatives that created greater information synergy and a clear path for individuals involved in the transition showing how they can adapt to the change. Inevitably, there will be people who can not or will not adapt and they were identified and accommodated early in the program. Design principle twelve is therefore that a shared information service needs both visible leadership and funding from the top of the organization.
H. Adaptability
As already stated, enabling a shared information service in a complex organization is typically a multi-year project involving many aspects of the organization’s strategic and operational functions. These projects have such a broad scope that they rarely run smoothly, and need to constantly adapt as the as priorities change and new technologies, legislation, competitors and partners become available. In fact, even once the shared information service is operational, it must adapt. This includes the structure of the service interfaces and payloads; the terminology used; the size of the supported workloads many change; new workloads will be added and others removed; the subject areas and types of data supported will evolve and new legislation and governance requirements will be defined. The scope of the organization will change as well as its internal structure and the individuals supporting it.
Thus adaptability is design principle thirteen in the shared information service. Much of the adaptability can be achieved by using metadata to define how the services are constructed and the functions that are called to transform and govern data. The rollout needs to be organized into a series of iterations. Each iteration should demonstrate some business value or a key principle of the shared information service.
IV. Conclusions
Whatever an organization’s starting point, it must eventually address six main cross-organizational initiatives to successfully operate a shared information service. These are:
- A data driven culture, where individuals and teams expect data to be easily available and actively use it to make decision and solve problems. Tied to this is a sense of responsibility towards data, where individuals include in their perception of their role in the organization how they consume, maintain and improve the data that they use.
- A business driven information governance program where there are business owners driving the definition of how data is to be used and managed in the organization. The business owners sent the controls that are encoded in metadata that drive how data is managed in the IT systems.
- A comprehensive, open metadata management service that details where the data in the organization is located, where it came from, what it means, how it is used today, how to get access to it, who is responsible for it, how it is governed and what it can be used for.
- A common information model, or more accurately, set of models that define the standards related to data. This includes the terminology used, how data should be grouped and organized and how it can be structured for display and exchange by IT services.
- An open, shared information service that acquires, manages and delivers data wherever needed in the organization along well defined information supply chains that support the appropriate business, analytical, software development and analytical lifecycles. This service is pattern-based and blends technology to meet different workload requirements, both for operational needs and the analysis necessary to continually improve the operation of the organization. It supports its own reference data and provides mapping services for connecting systems
- An IT operations and project management perspective that ensures all systems participate with the metadata service and data is accessible and exchanged
Partly because of the review of existing operations from a different perspective, and partly because the value of a data-centric approach to an organization’s operation, the benefits of a pattern-based, metadata driven approach to a shared information service that is accompanied by a comprehensive transformation program leads to a more adaptable and transparent shared information service and a flatter, simplified and more effective organization where data is deployed as an asset and used as a driver for success.
Acknowledgment
I wish to thank my IBM colleagues for their support in developing the information architecture concepts described in this paper. In particular, Tim Vincent, Dan Wolfson, and Bill O’Connell, who have each made a unique contribution to the art of information architecture.
References
- M Oberhofer, E Hechler, I Milman, S Schumacher, and D Wolfson, Beyond big data, IBM Press, 2015.
- T Vincent, Multispeed IT drives fast business experiments and empowered citizen analysts. InsightOut series, IBM Big Data and Analytics Hub, 2016, http://www.ibmbigdatahub.com/blog/insightout-multispeed-it-drives-fast-business-experiments-and-empowered-citizen-analysts
- M Chessell and H Smith, “Design patterns for information in a service-oriented environment. Service Technology Magazine, Issue LXXVII, October 24, 2013, http://servicetechmag.com/I77/1013-1
- A Dreibelbis, E Hechler, I Milman, M Oberhofer, P van Run and D Wolfson, Enterprise master data management, a SOA approach to managing core information. IBM Press, 2008.
- M Chessell and H C Smith, Patterns of information management. IBM Press, 2013
- M Chessell, F Scheepers N Nguyen, R van Kessel and R van der Starre, Governing and Managing Big Data for Analytics and Decision Makers. ITSO 2014,
http://www.redbooks.ibm.com/redpieces/abstracts/redp5120.html?Open
- M Chessell, G Sivakumar, D Wolfson, K Hogg, and R Harishankar, Common information models for an open, analytical, and agile world. IBM Press, 2015
- M Chessell, The case for open metadata and governance. InsightOut series, IBM Big Data and Analytics Hub, 2016, http://www.ibmbigdatahub.com/blog/insightout-case-open-metadata-and-governance
- M Chessell, D Radley, J Limburn, K Shank and N L Jones, Designing and Operating a Data Reservoir. SG24-8274-00, IBM 2015, http://www.redbooks.ibm.com/Redbooks.nsf/RedpieceAbstracts/sg248274.html
Photo: Beagle channel, Ushuaia, Argentina